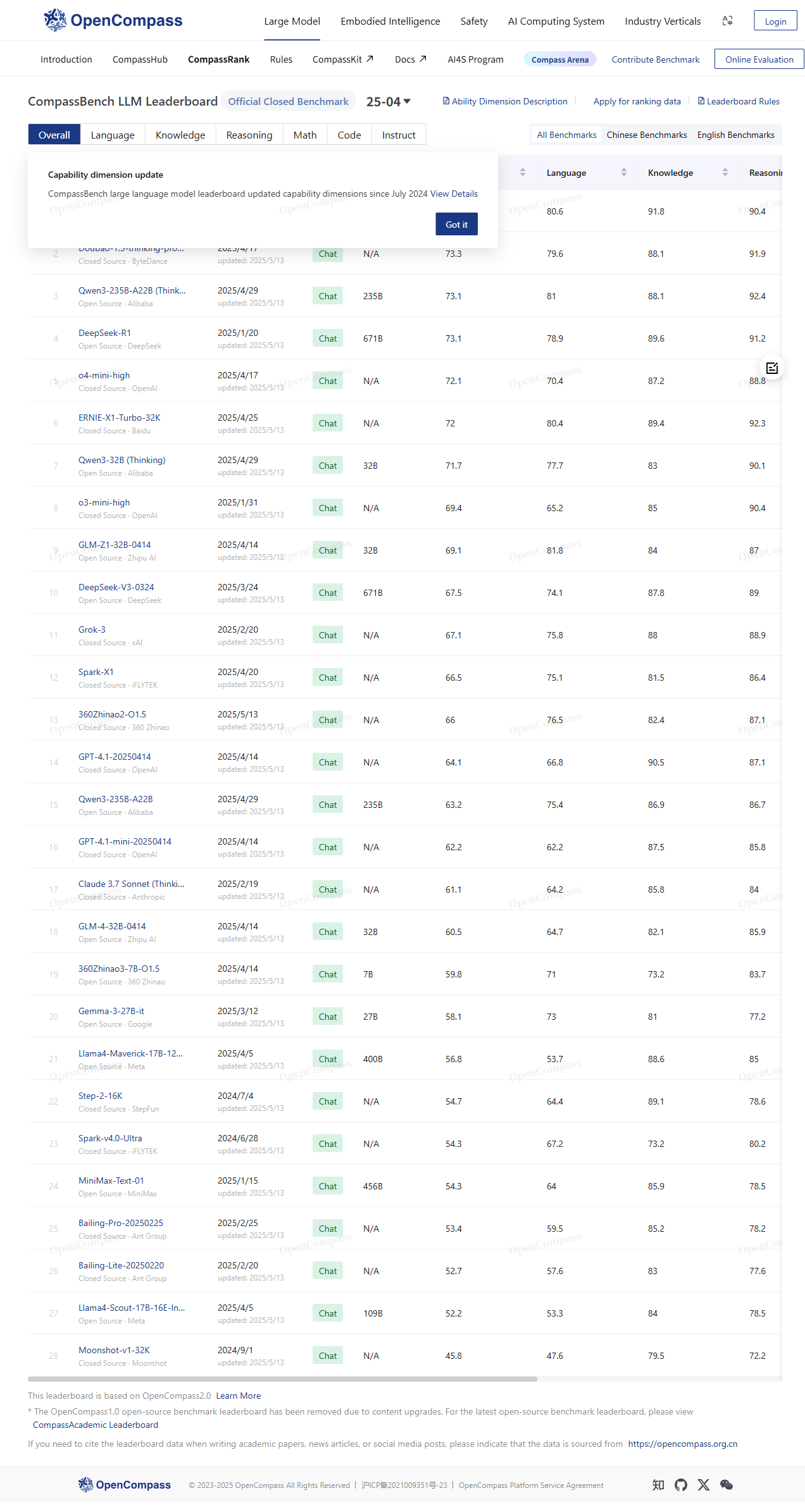
OpenCompass 司南大模型公开榜单由上海人工智能实验室 2023 年 8 月推出,定位“大模型能力体检中心”。平台以完全开源、可复现的评测框架为核心,持续对国内外主流大语言模型与多模态模型进行标准化测试,并实时发布权威排名。榜单数据每月更新,结果同步至 Hugging Face Spaces,面向学术界、产业界及开发者免费开放,旨在打造中文世界最可信的模型性能参照系。
OpenCompass 司南大模型公开榜单由上海人工智能实验室 2023 年 8 月推出,定位“大模型能力体检中心”。平台以完全开源、可复现的评测框架为核心,持续对国内外主流大语言模型与多模态模型进行标准化测试,并实时发布权威排名。榜单数据每月更新,结果同步至 Hugging Face Spaces,面向学术界、产业界及开发者免费开放,旨在打造中文世界最可信的模型性能参照系。