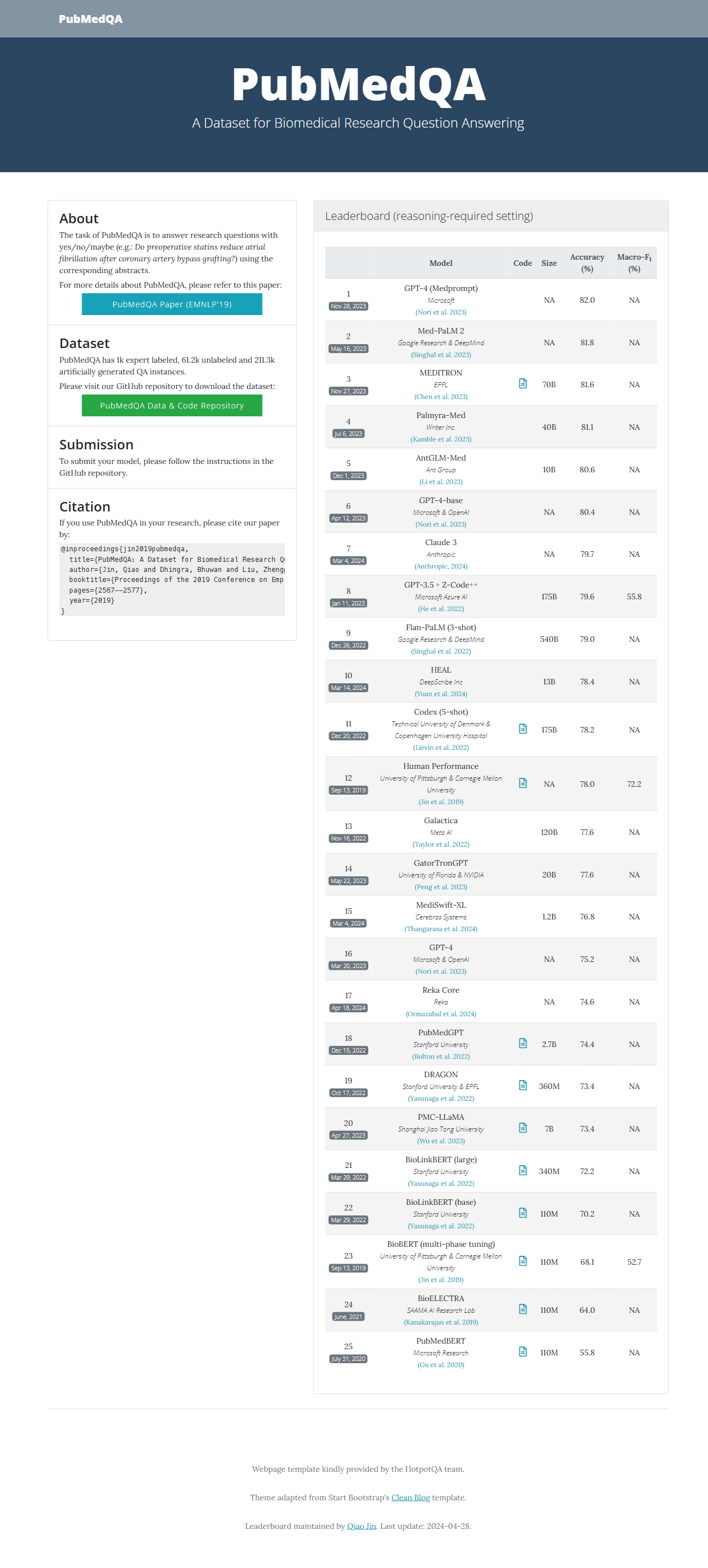
PubMedQA由卡内基梅隆大学团队于2019年发布,是目前唯一要求模型对生物医学摘要中的定量结果进行推理才能给出 yes/no/maybe 答案的公开数据集。站点提供约27.4 万条实例:1K 专家手工标注、61K 未标注真实摘要、211K 人工合成问答,覆盖心血管、肿瘤、药剂学等广泛主题。除数据下载外,官网实时展示18+ 个模型(BioBERT、Med-PaLM 等)的排行榜,并给出论文、代码与基线脚本,方便研究者复现与提交新结果。
PubMedQA由卡内基梅隆大学团队于2019年发布,是目前唯一要求模型对生物医学摘要中的定量结果进行推理才能给出 yes/no/maybe 答案的公开数据集。站点提供约27.4 万条实例:1K 专家手工标注、61K 未标注真实摘要、211K 人工合成问答,覆盖心血管、肿瘤、药剂学等广泛主题。除数据下载外,官网实时展示18+ 个模型(BioBERT、Med-PaLM 等)的排行榜,并给出论文、代码与基线脚本,方便研究者复现与提交新结果。